Petit moment de vie personnelle, je suis le daron d’une super petite fille de 5 ans. On lui a offert il y a quelques années une fabrique à histoires qui la suit partout. Vous connaissez le principe ? Vous choisissez un héros, un lieu, un objet, et la boite vous raconte une jolie histoire, bien construite, bien racontée. La boite (l’objet physique) est sympa, facile à utiliser, pour les 3 / 6 ans je conseille vraiment.
Et puis en discutant avec un ami, on s’est demandé si ChatGPT ne pourrait pas générer une infinité d’histoires dans une application un peu cadrée (mais pas trop) ! Et puis tant qu’à faire, pourquoi ne pas demander à ChatGPT de coder lui même cette application. C’est donc un petit défi pour me rendre compte à quel point je serais capable d’avoir une application fonctionnelle en en codant le moins possible moi-même. Il fallait que ça marche à la fin de la soirée pour que j’estime cela OK. Petite difficulté en plus, j’ai utilisé uniquement mon iPad, et Gitpod pour un environnement de développement en ligne.
Voici la discussion que j’ai eu avec ChatGPT en lui mettant quelques contraintes, comme le langage, ou le fait de n’utiliser aucune librairie externe :
Y être arrivé est déjà bluffant. Lisez la discussion, vraiment, qui aurait imaginé ça il y a encore quelques années ? Cependant, de temps en temps le code n’était pas fonctionnel. Il a fallu que j’ouvre la documentation de l’API de ChatGPT pour que j’oriente la discussion. Et l’orienter a suffit à ce que ChatGPT retombe sur ses rails, et s’excuse de son erreur. (ChatGPT ne se connait pas soit même, c’est presque décevant :p)
Cependant, j’ai le biais du développeur expérimenté (je crois pouvoir le dire à mon grand âge). Je savais à l’avance ce que je voulais, et ça change tout. Comment s’en sortirait un néophyte qui ne saurait pas débugger, ou sans aucune idée de l’implémentation attendue ? Mais quand je vois le travail en cours sur l’interprétation de code, notre façon de travailler devrait vraiment évoluer.
Code Interpreter will be available to all ChatGPT Plus users over the next week.
It lets ChatGPT run code, optionally with access to files you've uploaded. You can ask ChatGPT to analyze data, create charts, edit files, perform math, etc.
On parle de générer du code qui compilera, de sous traiter des traitements contextualisés à une discussion… Les prochaines années vont être intéressantes, et je suis curieux de voir comment nous allons nous approprier ces nouveaux outils.
Complément d’informations
Quid de la qualité de l’histoire ? Elle fait le job, sans plus. L’écriture est toujours un peu bizarre, mais elles font rire ma fille, ce qui étant quand même le but recherché. Je n’ai pas passé beaucoup de temps sur le prompt cela dit, il y a peut-être mieux à faire ? Je n’ai accès qu’à GPT3.5 à travers l’API, je verrai si le modèle GPT4 est plus sympa. Il devrait être généralisé sous peu.
Concernant le son, dans la première version du site, j’ai utilisé le Text to Speech natif au navigateur, et ce n’était franchement pas très convaincant. J’utilise maintenant l’API text to speech AI de Google Cloud qui a un rendu bien plus sympa! Mais il n’y a pas de continuité, pas d’intonation propre à l’histoire. Google devrait généraliser un nouveau modèle plus adapté aux histoires.
Bref, pour l’instant, la Lunii n’a pas trop à s’inquiéter. Rien de tel qu’une histoire bien écrite et bien racontée, et on est encore loin du compte. Faites marcher votre imagination et faites moi mentir !
Le 1er juin 2022, j’ai fêté mes 5 ans chez Karnott. Mon idée initiale était de retranscrire mon aventure en startup sur ce blog, avec un article par an.
Vous l’aurez compris, l’an 4 s’est perdu en cours de route. On va essayer de rattraper ça.
2021 a été une année en deux parties très contrastées pour nous. Vous n’aurez pas raté l’actualité de la Frenchtech: année record, avec plus de 11 Milliards d’Euros de levée de fonds. Et quand on est en startup, cette capacité de financement fait franchement envie. On s’est dit collectivement que c’était le moment et qu’il fallait profiter de la dynamique… Pourquoi pas nous ?
La préparation d’une levée de fonds
Une levée, c’est beaucoup de travail. En travail de fond, on s’assure qu’on n’a rien à cacher: sécurité des données, contractualisations avec les prestataires, propriété des éléments clés, code source à l’abri. En parallèle on travaille sur le plus important : le pourquoi. Pourquoi ai-je besoin d’argent dans mon équipe produit ? Une levée, c’est avant tout une équipe qui convainc des investisseurs qu’ils ont une vision, mais manque de moyens pour y parvenir au plus vite. On a besoin de cet argent pour embaucher, se structurer, pour accélérer. Nous avons donc construit notre vision produit court / moyen terme / long terme et nous avons mis sur papier la meilleure manière de l’atteindre si nous avions les moyens de nos ambitions. On parle de SaaS, d’une gamme de produits, de feature teams. De qui aurions-nous besoin, quand est-ce que nous devrions embaucher chaque personne, combien ça nous coûterait, etc… Le business plan sera aligné avec cette vision produit. Une feature team qui arrive ne produira de la valeur que X mois après, il faut aligner les planètes.
Et quand on a compris ça, on comprend un peu mieux ce qu’il s’est passé en 2021 dans les embauches et les salaires de la tech française.
Pour suivre le business plan établi lors d’une levée à plusieurs dizaines ou centaines de Millions, beaucoup de startups ont eu l’obligation d’embaucher vite vite vite, comme promis aux investisseurs. Comment on fait ça ? On paye au-delà du raisonnable. Les salaires ont franchement explosé dans certains cas. Je sais que cet avis n’est pas très populaire, vous entendrez que les salaires ont augmenté en 2021 pour d’autres raisons. Je peux citer, entre autres choses : – les boites françaises sont en concurrence dans le recrutement avec les boites étrangères, le remote se démocratisant. Et à l’étranger, ça paye mieux. – les boites françaises avaient de toute façon du retard – C’est juste la loi de l’offre et la demande mon bon monsieur.
C’est sûrement en partie vrai, mais je pense que c’est avant tout le cumul de ces raisons avec un afflux massif de capitaux, en plus d’un marché de l’emploi historiquement tendu dans la tech pour les profils qualifiés.
À titre personnel, c’est une situation que je n’ai pas très bien vécu, n’ayant pu retenir un des membres de l’équipe.
Et donc ?
Et donc, nous n’avons pas levé malgré des propositions reçues, les termes ne nous convenant pas. Une bonne levée est une levée au bon moment, où tu te sens prêt à accélérer dans de bonnes conditions. Cela faisait 4 ans que nous avions la tête dans le guidon, nous avions accompli beaucoup de choses, mais une intuition nous laissait penser que pour lever dans de bonnes conditions, nous avions besoin d’assainir nos fondations. Un autre chemin était possible : celui d’être rentable et autonome.
Une startup rentable ? Vous êtes sérieux ?
Oui, c’est possible et on est même en train de se dire qu’on a eu le nez fin. La guerre en Ukraine, les conséquences long terme du COVID en Asie, les galères d’approvisionnement, l’inflation… Les investisseurs sont en train de serrer la visse et lever n’est plus aussi simple. Gare aux entreprises qui vont avoir besoin de fonds en 2022 ou 2023 !
? La bonne nouvelle pour nous, c’est qu’on a plein de super clients ! Karnott, ce sont des milliers de clients, des dizaines de millions de Kilomètres parcourus et des millions d’Hectares travaillés et analysés avec notre solution. On en est fier et on a raison de l’être. Bref, la rentabilité n’est pas une chimère lointaine… C’est faisable, on y croit.
Cela étant dit c’est aussi une trajectoire diamétralement opposé à ce qu’on avait planifié ces derniers mois : du jour au lendemain, on prend notre jolie roadmap, nos plans de recrutement de 50 personnes et on met tout de côté. Moralement, ça fait quelque chose…
L’idée est donc de réduire les coûts et de maximiser la croissance. Comme toute entreprise me direz-vous ? Non. En 15 ans, dans la tech, j’ai rarement vécu dans un environnement technique contraint financièrement. Dans l’aéronautique, le bancaire, le retail, j’ai toujours travaillé dans des environnements où on regardait peu les coûts techs, qui étaient pris comme une fatalité pour aller où on le souhaitait. J’ai souvent trouvé ça malsain et étrange, sans arriver à comprendre ce qui n’allait pas. La réalité, c’est qu’à petite échelle, le retour sur investissement d’une équipe produit est quelque chose de quantifiable. On voit les salaires, les coûts SaaS, les coûts d’infrastructure, on mesure l’argent qui rentre par la valeur produit générée et on doit constater un tout cohérent. Tout simplement.
En tant que CTO, j’ai eu plusieurs défis.
1er défi : Le FinOps
Mes camarades le savent, je suis pénible sur la gestion de l’infrastructure. Le Cloud, c’est cool, mais on est toujours à 1 clic de la dépense facile. Et bien non, au diable le Darwinisme Numérique et son abondance (interview passionnante cela dit), la sobriété a du bon. On passe du temps à optimiser l’utilisation du CPU réservé, des services qui tournent, de l’espace disque alloué. (Saviez-vous qu’avec TimescaleDB il est simple de compresser les vieilles données ?). C’est un travail, mais je suis certain que tout ce qu’on a appris et mis en place nous donneront des clés de scalabilité et de pérennité.
2nd défi : Gérer toujours plus, avec les moyens du bord
OK, l’équipe ne grandit pas. Pourtant, nous avons de nouveaux clients, plus de données, plus de défis. Mais aussi plus de support. Arriver à créer de la valeur avec un support chronophage devenait impossible. Alors on se calme, on qualifie mieux les tickets, on mesure et on se concentre sur ce qui cloche. On s’est vite rendu compte que le support reposait sur quelques épaules et qu’individuellement on n’avait pas toujours la compétence requise pour résoudre le ticket. Alors nous avons mis en place des astreintes : chaque jour de la semaine, un membre différent de l’équipe est forcément de support et il doit documenter ce qu’il fait. Cette journée-là est dédiée à dépiler du ticket pour la personne d’astreinte. Obligation aussi de laisser des commentaires, au moins un début d’analyse et un travail en cours pour la personne du lendemain. On se partage le travail et les soucis. Cela a permis à l’équipe de mieux prendre conscience des problèmes de qualité, d’outillage interne manquants, d’en prendre acte, de coder quelques « helpers » et en quelques mois, magie, le nombre de tickets a été divisé par deux.
J’ai écouté d’ailleurs un super podcast avec Mathilde Lemée qui parle de sur-qualité et du fait qu’il y a un temps pour tout dans la vie d’une startup. Je ne peux qu’appuyer son propos.
Conséquence directe : nous avons toujours été en capacité à délivrer de la valeur (et donc du MRR), avec une certaine sérénité sur la qualité de ce qui était délivré.
3ème défi : Faire plus avec moins n’est pas sans conséquence
Comme je suis sympa, je vous partage ma recette d’un petit cocktail maison : – Un objectif d’entreprise clair à atteindre à tout prix – Une équipe à qui ça tient à cœur de réussir – Le télétravail, qui rend plus floue la coupure travail / vie de famille – Une communication entre les services plus basée sur l’émotion que sur les chiffres et les faits – Des résultats avec des bons jours… et des moins bons.
Et vous avez la recette pour un petit burn-out.
En mai 2022, j’ai ressenti une profonde fatigue. Du genre à se sentir vraiment nul, toujours énervé, grincheux (plus que d’habitude :p ) et surtout impuissant à réussir. Heureusement pour moi, j’ai pu très vite compter sur ma compagne qui m’a simplement dit « prends une pause ». Et j’ai pris une pause.
Je sais qu’il est difficile d’appréhender les signes d’un burn-out. On se dit toujours que ce n’est qu’une passade… Mais couper quelques semaines m’a permis de remettre un peu les pieds sur terre et surtout me redonner des certitudes. Le plus beau, c’est que toute l’équipe, comme d’habitude, a fait preuve d’une solidarité et d’un soutien sans faille. Merci pour ça, je suis toujours aussi chanceux de bosser avec vous <3
Chaque cas est différent et le burn-out est un sujet sensible, mon seul conseil sera de faire preuve d’humilité. Parlez-en c’est déjà beaucoup. Si vous ne changez rien, rien ne changera.
Et maintenant ?
C’est mieux. On élimine toute prise de décision basée sur l’émotionnel. On mesure tout, on essaie d’arriver avec des arguments et on se dit tout. On a d’ailleurs mis en place la rétrospective de Comité de Pilotage ! Expérience intéressante, on applique les rituels agiles aux membres du Copil, pas forcément habitués à ce genre de choses. Globalement, quand on se rend compte que des échanges ne sont pas assez fréquents, honnêtes ou naturels, je trouve que les ritualiser est une bonne chose. Les retours sont bons et les relations assainies.
Cet article a été le plus dur à écrire de la série. Je crois aussi que c’est le plus important. La vie en startup n’est pas un long fleuve tranquille basé sur le succès et les millions qui coulent à flot.
Cela fait plusieurs mois que nous avons mis en place un nouveau rituel avec l’équipe : le Mob Code Review et il est temps d’en donner un petit feedback. Comme toujours dans le développement, cet article est à nuancer avec votre propre contexte d’équipe. Prenons juste le temps d’expliquer les pour et les contre d’une méthodologie qui a changé nos journées.
Définition
On connait le Mob Programming… Le Mob Code Review, est basé sur le même principe : faire la code review en équipe, au même moment, sur un sujet donné.
Retour en arrière…
Déjà, un peu de contexte. Karnott, c’est une équipe produit de moins de 10 personnes, avec beaucoup de compétences différentes. Système embarqué, Gestion de base de données, de l’infra, du soft backend, du front, du mobile… Et pour faire tourner tout ça, une multitude de langages différents (citons Golang, Java, Kotlin, C, Rust, SQL, Javascript, Bash…), et ne parlons même pas des frameworks utilisés dans chaque brique technique. Le choix du langage n’a jamais été un sujet chez nous, on fait au mieux avec ce qu’on maitrise et la problématique à traiter, Jusqu’au jour où cette variété de compétences est devenue un frein à notre vélocité.
Pourquoi cette perte de vélocité ? Il y a bien longtemps qu’on avait identifié le Bus Factor : laisser quelqu’un dans son coin avec ses compétences et ses connaissances fonctionnelles était inacceptable. L’une des manières de forcer le partage de connaissance, c’est de passer par la case code review. (En plus des divers avantages liés à la qualité de code, bien entendu).
Un Kanban des plus classiques
Malheureusement, les tâches avaient tendance à s’accumuler en To Review. Nous en avons parlé et avons identifié deux raisons principales :
Faire de la review, c’est prendre le temps de le faire. Je suis sûr que tout le monde a eu ce souci à un moment ou à un autre : il faut s’interrompre dans sa propre tâche, se plonger dans une autre, en comprendre la complexité, etc. Bref, faire de la review, c’est une vraie tâche en soit, et ce n’est pas si simple de savoir quand le faire.
On ne se sent pas toujours pertinent à faire la review. Trop éloigné de son domaine de compétence, technique ou fonctionnelle…
Premier test : à la suite du daily
Quand une solution s’offre à nous, et qu’elle nous parait pertinente, nous l’intégrons aux rituels d’équipe pour ne pas être tenté de le squizzer. Il faut vraiment jouer le jeu. Nous nous sommes mis d’accord sur un daily à 9h30, qui permet d’identifier les tâches à review, suivi d’une review collective et systématique.
Avantages : – On a découvert le Mob Code Review tous ensemble – Aucune tâche ne pouvait plus être laissée de côté – L’équipe s’est vraiment intéressée à tous les sujets, même si on sortait de notre zone de confort – Uniformisation des pratiques de développement
Inconvénients : – Si plusieurs tâches sont à review, ça peut être chronophage. – Alors qu’une partie de l’équipe se sent plus productive le matin à coder, enchainer tous les jours daily + review, la matinée était rapidement perdue.
Fonctionnement actuel
Comme toujours, on prend les feedbacks, et on itère pour améliorer les choses. On a donc déplacé la review au début d’après-midi, et on essaie d’être là, sauf impératif. Pour que tout le monde soit au courant de la nécessité d’une review, on a mis un petit rappel slack qui apparait à 11h tous les jours :
It’s a Yesss !
Déroulé
Mais comment ça se passe, une mob review ? NB : Notre équipe est en full remote depuis plusieurs mois / années maintenant (ça fait bizarre de le dire d’ailleurs). Donc premier conseil, choisissez une plateforme de streaming qui permet de partager son écran en haute def, ce qui permet la lecture de code. Exit Discord, on se retrouve sur Google Meet.
Le / la responsable du code va présenter : – Le but de sa Pull Request – Le contenu, plus ou moins détaillé – Potentiellement il y aura une démo S’en suivront un jeu de questions, de remarques, on voit si toutes les choses obligatoires y sont (documentation / tests).
Si tout est OK, la PR pourra être mergée dans la foulée. Et si ça nécessite du travail en plus et bien pas de problème, la personne retravaillera dessus quand elle le pourra.
Alors, en avez-vous besoin ?
Si vous avez une équipe avec des compétences homogènes, sur un scope fonctionnel bien délimité, je ne pense pas qu’il faille aller jusque là.
Mais si vous voulez faire monter des personnes en compétence et améliorer la communication horizontale entre les membres, c’est un très bon outil. Chez nous, il en a découlé des choses rigolotes, comme du Pair Programming entre des personnes qui n’avaient, jusque là, pas grande intéraction.
Des tâches qui ne peuvent plus rester bloquées, une équipe soudée, un partage de connaissance, bref, on valide tous. L’investissement en temps est le bon, dans notre contexte, même s’il est non négligeable. Mon conseil sera simplement d’écouter l’équipe pour arriver à trouver le bon équilibre.
Connaissez-vous Home Assistant ? C’est un chouette logiciel de domotique, compatible avec une multitude d’objets, de protocoles…. Vous pourrez facilement faire des tableaux de bord, et avoir des interactions assez poussées avec vos objets à condition d’accepter d’écrire un peu de YAML. Sa communauté est vraiment dynamique, les plugins sont nombreux et on trouve à peu prêt ce que l’on veut.
Par défaut, Home Assistant va utiliser un stockage SQLite. C’est pratique, ça ne réclame pas de dépendance particulière, et ça fait le job. Mais par défaut, et je ne comprends franchement pas l’idée, nous n’avons qu’un historique de 24h sur nos différents capteurs. Dans mon cas j’ai un dongle ZWave, avec un capteur de température Fibaro:
L’oeil de Sauron… Ceux qui savent, savent.
Et ça me frustre. Avant j’utilisais Domotizc et je n’avais pas ce soucis. On avait un véritable historique, et ça me permettait d’analyser un peu l’effort énergétique que je devais mettre dans ma maison pour maintenir une certaine température.
Pour votre utilisation personnelle, toutes ces solutions peuvent convenir en fonction de vos connaissances ou vos affinités.
Quand j’ai vu la présence de Google Pub/Sub, j’ai réalisé que je pourrais très vite réaliser des tableaux de bord grâce à la suite Google à un cout proche de 0€. (OK, tout service a un prix. Mais je ne souhaitais pas consacrer de réel budget à ce service).
Quelle est l’idée ?
Pousser les données Home Assistant dans Pub/Sub
Pub/Sub, c’est un message broker. L’idée est donc de recueillir tous les événements Home Assistant grâce à ce plugin : https://www.home-assistant.io/integrations/google_pubsub/ Ce plugin est préinstallé dans Home Assistant. Vous n’aurez donc qu’à modifier le fichier configuration.yaml selon la documentation du plugin. Chez moi, cela ressemble à ça :
Cela me permet de pousser dans pubsub uniquement les évènements relatifs à mon fibaro, et à mon thermostat Nest.
OK, des messages arrivent dans Pub/Sub, qu’est ce que j’en fais maintenant ?
Déjà, vérifions si des messages arrivent. Les messages sont publiés dans un « topic » ou « sujet » en français.
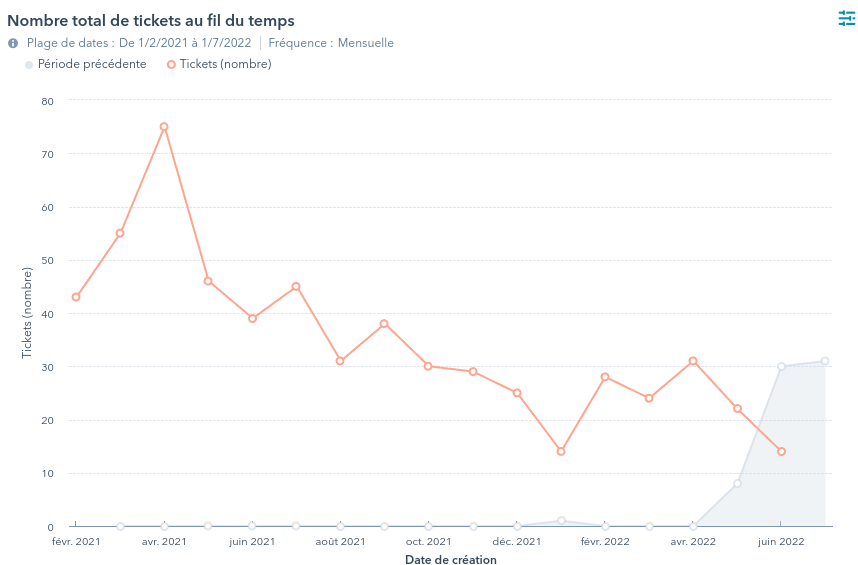
Bonne nouvelle en ce qui me concerne, on voit quelques messages passer. Home Assistant parle, et assez peu (ce qui est aussi une bonne nouvelle, les filtres configurés ont l’air de fonctionner).
Plusieurs options s’offrent maintenant à vous pour faire quelque chose de ces messages. Pub/Sub vous propose deux options pré-construites : « Exporter vers BigQuery » ou « Exporter vers Cloud Storage ». Ces tâches, qui vont en effet fonctionner, sont basées sur Dataflow. C’est une solution basée sur Apache Beam qui permet d’exécuter du code sur de volumineux flux de données avec différents patterns (agrégation, filtre, transformation…). Je ne vous conseille pas son utilisation pour ce cas précis, juste parce que vous allez le payer cher (€) pour pas grand chose.
Une autre option m’intéresse un peu plus. En haut de l’écran, on peut lire une option « Déclencher une cloud function ». Qu’est ce donc ? C’est la possibilité d’exécuter un bout de code, simple et unitaire, pour chaque message qui arrive. Et c’est exactement ce que nous souhaitons vu l’objectif : lire les messages et les stocker quelque part. La volumétrie impliquera un coût proche de 0.
Pré-requis : Création du dataset BigQuery
Avant de s’occuper de la Cloud Function, allons préparer la base de données. Pour cela, rien de plus simple, on se connecte à la console d’administration de BigQuery pour y créer un dataset. Vous pourrez choisir l’emplacement des données. Dans l’exemple de code que je vais vous donner, j’ai choisi de ne garder que 3 simples informations : – Le device id – La date de l’évènement – La valeur associée C’est la définition d’une Time Série…
Un dataset, une table et son schéma.
Création de la Cloud Function
Maintenant que BigQuery est prêt à accueillir nos données, allons les déverser. Sur l’écran de votre sujet Pub/Sub, cliquez sur « Déclencher une cloud function ». Cela vous amènera à un écran pré-rempli où vous pourrez mettre un nom à votre cloud function, une région d’exécution (par habitude je prends local, Europe-West1 😉 ). Et si vous voulez utiliser un bout de code pré-écrit, il y aura 3 variables d’environnement d’exécution à fournir dans les paramètres avancés :
Soit vous essayez de lier ce dépot que vous aurez forké à votre compte GCP, soit vous copiez coller le contenu dans l’éditeur intégré. Le code est en golang 1.13, le point d’entrée étant une fonction Main
function.go, go.mod et go.sum
Et plus qu’à déployer.
Si tout va bien, une fois déployée, vous devriez voir votre fonction se déclencher à chaque nouveau message dans Pub/Sub ! Sur l’écran d’administration de la cloud function, vous trouverez un onglet pour accéder aux logs générés.
La fonction est lancée, le message qui provient de Home Assistant est loggé et doit être sauvé dans BigQuery
Et normalement, votre table BigQuery devrait aussi s’alimenter…
De la donnée ! Victoire !
Comment en faire un graphique ? Direction Datastudio
Datastudio permet de faire des tableaux de bord en se connectant à plein de sources de données différentes, dont BigQuery. Lors de la création d’un nouveau rapport, vous allez pouvoir ajouter des données au rapport.
BigQuery parmi les centaines de connecteurs disponibles…
Vous allez pouvoir pointer vers la table Data du bon dataset. Une fois que la source de données est ajoutée, vous allez pouvoir éditer le rapport. En haut à droite, différents types de graphiques seront disponibles, dont un qui me parait pertinent : « Graphique de série temporelle lissée ». Comme on parle de température, un lissage me parait approprié.
Une date, un type et une valeur : on est bien dans la timeserie
Et magie…
La température dans mon bureau… On voit quand les moniteurs sont allumés, pas besoin de chauffage.
Conclusion
Tout ça pour ça me direz-vous ? BigQuery est un outil extrèmement puissant. Pour une volumétrie Domotique, vous n’aurez jamais à vous soucier de quoi que ce soit, à condition de ne pas réclamer une réactivité trop grande. La puissance est illimitée, les couts de stockage ridicules. Intéressez-vous à cet outil. Datastudio possède une grande variété de données, et vous serez capable de croiser les informations, peut-être avec une autre source de données que vous avez quelque part ? On aura aussi vu du PubSub, de la Cloud Function, bref une chaine de traitement complète autour de l’IOT ! Et le tout sera scalable… Amusez-vous en jouant avec les filtres de configuration Home Assistant par exemple !
Fin avril, avec Hubert Sablonnière, nous avons eu la chance d’être conviés par Cyril Lakech et Damien Cavaillès dans les bureaux de nos amis de WeLoveDevs pour deux heures de discussion. Pendant ces deux heures, avec Hubert nous avons retracé nos parcours en société de service, ce qu’elles nous ont apportés dans nos carrières, et ce qu’on a mis en place pour tenter de nous différencier et de progresser.
Dans cet univers assez lisse que sont les sociétés de service, il s’agit bien de trouver un vecteur de différenciation pour faire son trou (vous faites partie « des devs »). Pour Hubert, c’est passé par l’expertise technique et son succès en tant que speaker reconnu. Pour moi c’est passé par mon travail dans les communautés tech par lesquelles je suis passé, et plus particulièrement le GDG Lille. Et c’est là qu’il y a débat : ça nous a demandé beaucoup de travail personnel sur notre temps libre, même si nos ESN respectives nous ont soutenues comme elles pouvaient, que ce soit en temps disponible (« non facturé ») ou en sponsoring… Bien entendu elles y ont gagné en visibilité et en image developer friendly. Bref, le débat n’est pas clos, n’étant pas tous égaux devant l’investissement personnel que chacun peut mettre en dehors des heures de bureau.
Au final avec Hubert nous étions d’accord sur les raisons qui nous ont fait changer de parcours. Nous voulions choisir les structures dans lesquelles nous travaillons, des structures avec un impact concret sur ses utilisateurs, conformes à nos valeurs. Et surtout, nous voulions nous sentir vraiment utiles à nos entreprises.
La recette du bonheur est bien entendu plus complexe…
Je tenais à mesurer un peu mes propos. Oui, j’aime mon job, mes collègues, mon impact dans l’entreprise et ce que nous faisons tous les jours. Cela dit, parlons un peu plus des différences entre mon ancienne vie de développeur en ESN et ma vie actuelle en startup.
Je parle des sociétés de service, parce que c’est mon expérience. Mais concrètement, la vie du développeur en société de service se résume beaucoup à la vie chez son client. Et statistiquement, vous avez plus de chance de travailler en sous traitance pour des grands comptes que pour une PME. Et c’est là un point important : mon article devrait sans doute s’appeler Grand Compte versus PME, quelles différences pour un développeur ?
Travailler en mode Projet
Je n’ai compris que très récemment à quel point l’équipe technique était une entité bien à part dans une grande structure. Oui une équipe technique sur un projet peut avoir une pression folle, un management toxique, le projet peut-être compliqué et n’avoir aucun sens ni technique, ni produit, ni rien. On est tous d’accord. Mais mon propos est tout autre : la mission de l’équipe se résume souvent à réaliser un service bien défini.
Un input : le besoin, un output : le produit conçu
Bon, dans la vraie vie de la grosse entreprise ce n’est pas aussi binaire bien entendu. Votre projet évolue dans un environnement complexe, qui vous dépasse. D’un côté vous avez les moyens d’agir, la main d’œuvre, les outils. D’un autre côté, beaucoup de décisions sont prises à l’échelle de l’entreprise, et votre équipe ne pourra que les subir. Vous avez envie de faire bouger les lignes ? Il faudra vous confronter à une inertie très forte. Convaincre, sortir des KPI, construire sa roadmap autour de convictions fortes, et puis du jour au lendemain, non. Maintenant chez <GRAND_GROUPE> on fait comme ça et pas autrement. Ce manque de sens, d’autonomie et cette incapacité à changer les choses m’ont fait migrer vers la startup.
Et travailler en mode…. Startup ?
Quand j’ai rejoint Karnott, j’ai surtout rejoint deux personnes qui avaient une idée et la vision d’une agriculture connectée au service de l’agriculteur. Il faut se rendre compte qu’un « founder » en startup, c’est quelqu’un qui croit dur comme fer en son idée et qui met toute l’énergie pour y arriver. Et il en faut de l’énergie pour tracter tout le monde. De mon point de vue c’est un mélange d’enthousiasme, de force de persuasion, d’énergie, d’insouciance et de sentiment d’invincibilité. Soyons réalistes, je ne coche pas toutes les cases et je ne me lancerai jamais seul 🙂
La première conséquence de travailler avec des entrepreneurs, c’est qu’ils se réveillent souvent le matin avec une nouvelle idée. Un problème ne reste jamais longtemps un problème, ça se transforme en idée, voire en opportunité.
J’ai essayé de lister quelques difficultés courantes auxquelles il est difficile d’échapper dans une jeune startup. Peut-être que certains points sont communs avec les grosses entreprises mais je pense que ça sera toujours exacerbé par le contexte startup.
Premier point : ambitions, vélocité d’équipe et réaction face à l’échec
Les ambitions sont toujours énormes. On va bouleverser le marché, aller plus vite que les autres, faire les choses mieux avec une expérience utilisateur incroyable. On fait du LEAN, on sort un MVP, on trouve nos premiers utilisateurs, on se sent fort. On a de la traction (croissance), et maintenant il faut convertir. Faire de son MVP un produit qui a de la gueule… Il n’empêche qu’on est toujours 3 développeurs, que les stories s’allongent à l’infini, et que les idées arrivent toujours en nombre.
Viennent aussi les premières désillusions commerciales. Il faut changer de fusil d’épaule, alors qu’on avait entamé le super chantier tech dont on parlait depuis des mois. Hop, on met tout ce travail dans un tiroir, et on repart d’une feuille blanche. Moralement, techniquement, c’est dur.
Les équipes techniques ont besoin de stabilité et de sérénité : ce n’est pas l’apanage d’une startup.
Second point : la variété de sujets à traiter
Cette capacité à mettre son travail en suspens pour travailler sur autre chose, ça n’est pas lié qu’au produit. Une startup, c’est une entreprise complète avec son équipe commerciale, sa compta, sa gestion du support, son comité de pilotage… Une startup, c’est une seule équipe dont vous faites partie. Et cette équipe, pour avancer sur plein de sujets, elle a besoin de vous. Vous n’aimez pas faire du support ? Le marketing / SEO n’est pas votre panacée ? Faire des tableaux de bord de suivi ne vous intéresse pas vraiment ? Et quid de la facturation ? Pourtant on a vraiment besoin de vous, et c’est toujours urgent. Alors il faut être malin, trouver les solutions les plus efficaces pour mettre tout en place à moindre coût. D’ailleurs ce n’est pas pour rien que beaucoup de solutions no-code émergent ! Objectif : réduire la frustration des différentes personnes de la startup en les autonomisant, et permettre à l’équipe produit de se concentrer sur… le produit.
Chez Karnott, nous sommes friands de plein de SaaS pour ne pas avoir à tout faire nous-même, mais ce n’est pas magique. Et quand quelqu’un à côté de vous a besoin d’aide sur un sujet hors de votre scope principal, et bien vous l’aidez, c’est normal.
Troisième point : la charge mentale
Si vous êtes l’archétype du développeur le casque vissé sur la tête qui ne supporte pas être dérangé tant qu’il n’a pas fini sa tâche, je doute qu’une jeune startup soit faite pour vous. On peut vite être noyé par une myriade de demandes en tout genre, autour du produit mais pas que, et urgentes mais pas que. On s’implique sur nos tâches en cours et on essaie de bien les faire. Ça, ma carrière en ESN m’a appris à gérer la chose à-peu-près correctement. Mais par dessus tout ça, il y a la vie de la startup, les réflexions sur le produit, les défaites et les victoires de chacun, les changements de cap, les implications financières, les perspectives et les imprévus. Je vois ça comme un carrefour permanent, et on doit choisir le meilleur chemin : un océan de possibilités dans lequel il est possible de se noyer à tout moment.
Une autre pression permanente est celle de la réussite. Vous êtes peu nombreux, pressés, et vous devez sortir un produit de qualité. Vous savez que ces trois ingrédients ne font jamais bon ménage. Pouvoir mettre en production n’importe quand ne veut pas dire proder n’importe quoi : personne d’autre que vous ne sera là pour réparer une bêtise à 2 heures du matin si toute l’infra tombe. Vos actions ont un impact sur vos clients, mais aussi sur vos collègues. C’est un point totalement sous estimé par tout le monde, jusqu’au jour où rien ne se passe comme prévu.
Mais alors comment gérer tout ça ? On m’aurait menti, c’est tout nul la startup ?
Cet article n’est pas un article contre les startups, c’est une mise en garde. Je n’ai jamais entendu parler d’une réussite incroyable en startup où le chemin a été tout tracé, sans que les équipes n’aient douté, ou galéré à un moment.
Lorsque Damien Cavaillès nous demande l’ingrédient du bonheur, je réponds « avoir un travail où on peut avoir de l’impact », et je le pense toujours. Être confronté tous les jours à un océan de possibilités, c’est difficile, mais c’est aussi la chance de faire de vrais choix, pour le meilleur ou pour le pire.
Quelques conseils, pour ce que ça vaut :
Prenez soin les uns des autres. La charge mentale n’est pas une invention, ça peut être vraiment difficile. Je pense qu’un élément de toxicité, c’est de penser que la personne à côté de vous peut tout encaisser.
On foire ensemble, on réussit ensemble. Autonomisez les équipes, ne cherchez pas à tout contrôler. Quand tout le monde est dans son rôle et se sent libre de ses choix, la personne avancera sans contrainte et sera plus efficace. Et puis si vous êtes son manager, cela vous déchargera d’un poids. L’échec ne sera pas son échec, et la réussite ne sera pas la votre. On vit l’aventure ensemble. L’équilibre est à trouver. En tant que CTO, je cherche à distiller la bonne quantité d’information pour rendre les équipes autonomes sans pour autant les surcharger mentalement. Exercice de funambule.
Identifiez bien les rôles de chacun. Pour que le point précédent réussisse, il me paraît important que chacun sache exactement quelle est sa place dans l’entreprise. Ne nous marchons pas sur les pieds…
Conclusion
J’adore les gens avec qui je bosse, j’adore mon job. En 2021, en tant que développeur, nous avons le luxe de pouvoir choisir dans quel contexte travailler. Une ESN n’est pas un mauvais choix, une grosse entreprise non plus, tout comme la startup. C’est juste différent, et il est important d’avoir toutes les clés en main pour choisir.
Il reste une dernière catégorie, l’entreprise de taille moyenne (50+) avec une belle équipe technique. Sur le papier, j’ai l’impression que cette typologie apporte une certaine stabilité dans l’équipe tout en donnant les moyens d’agir à son échelle. Prochaine étape pour Karnott?